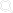山东大学健康医疗大数据研究院数据存储平台是整合了历年调查报告数据、医院体检数据、省厅数据、基因数据、影像数据等多种综合数据的统一数据管理平台。实现了将结构化、非结构化数据以及各个来源的数据进行统一管理,并提供一站式数据服务。用户可以通过平台查看,申请不同来源的数据供自己使用,而无需关心数据具体是在哪里存储以及如何存储的问题。数据存储平台底层存储由两部分组成,存储传统结构化数据的MPP数据库以及处理非传统结构化数据以及非结构化数据的Hadoop体系。
MPP(分布式数据库)采用的是Greenplum(以下简称GP)
GP是一种基于PostgreSQL的分布式数据库集群,它是由数个独立的PostgreSQL数据库服务组合而成的逻辑数据库整体。是一个纯软件解决方案; 硬件和数据库软件没有耦合,适应性更广泛。GP数据库在几乎所有Linux/Unix平台均能良好地运行。GP属于典型的OLAP解决方案,是基于数据仓库的息分析处理过程,是数据仓库的用户接口部分。是跨部门的、面向主题的。
GP的优点特点如下:
开源,源代码开放,免费,有效降低投资运营及定制成本。
MPP大规模并行处理架构,可在X86服务器上实现自动并行计算,有效降低海量系统对硬件的强依赖性。
成熟稳定的高可用方案,通过优秀的架构设计及相关手段能实现企业级高可用性、高扩展性。
支持SQL语言,可以更加简单快速的上手。
基于以上特点,采用GP存储常规结构化数据,可以解决大量数据存储的情况下,有效的将传统关系型数据库上的业务操作过度过来。 但是仍存在部分数据是GP无法直接处理的,如医学影像数据(图片)、基因数据等,所以在使用GP的同时,采用Hadoop体系,实现非结构化以及大体量的结构化数据的存储运算。
Hadoop体系主要使用Hbase来处理非常规的结构化数据,在上层搭建ElasticSearch用来丰富以及优化Hbase的查询,并辅以HDFS处理非结构化数据。
HBase是建立在Hadoop文件系统之上的分布式面向列的数据库
它是一个开源项目,是横向扩展的。HBase是一个数据模型,类似于谷歌的大表设计,可以提供快速随机访问海量结构化数据。它利用了Hadoop的文件系统(HDFS)提供的容错能力。它是Hadoop的生态系统,提供对数据的随机实时读/写访问,是Hadoop文件系统的一部分。人们可以直接或通过HBase的存储HDFS数据。使用HBase在HDFS读取消费/随机访问数据。 HBase在Hadoop的文件系统之上,并提供了读写访问。
HBase的优点特点如下:
HBase线性可扩展。
它具有自动故障支持。
它提供了一致的读取和写入。
它集成了Hadoop,作为源和目的地。
客户端方便的Java API。
它提供了跨集群数据复制。
同时Hbase特殊的存储机制,使得Hbase中的“表”在数据处理上更加具有优势。
大:一个表可以有上百万列,列数受限于物理存储。
面向列:面向列(族)的存储和权限控制,列(簇)独立检索。
稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
无模式:每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一张表中不同的行可以有截然不同的列。
Elasticsearch(以下简称ES或Esearch)
Esearch是一个实时分布式和开源的全文搜索和分析引擎。 它可以通过restful接口访问,并使用简洁的JSON文档来存储数据。同时,由于Esearch是基于Java编程语言,这使Esearch能够在不同的平台上运行,使用户能够以非常快的速度来搜索非常大的数据量。将Esearch与Hbase结合使用,大大增强了Hbase对各种复杂查询的支持能力。
Esearch的优点特点如下:
开源
Esearch是受欢迎的企业搜索引擎之一,目前被许多大型组织使用,如Wikipedia,The Guardian,StackOverflow,GitHub等。
Esearch使用非标准化来提高搜索性能。
Esearch可扩展高达PB级的结构化和非结构化数据。
Esearch可以用来替代MongoDB和RavenDB等做文档存储。

Copyright © 国家健康医疗大数据研究院